12月26日晚,杭州一家专注于人工智能基础技术研究的公司发布了重要进展——DeepSeek - V3首个版本正式上线并对外开源。这一成就标志着人工智能领域的又一重要突破,无疑引发了业界的极大关注和激动。
性能比较中的亮眼表现
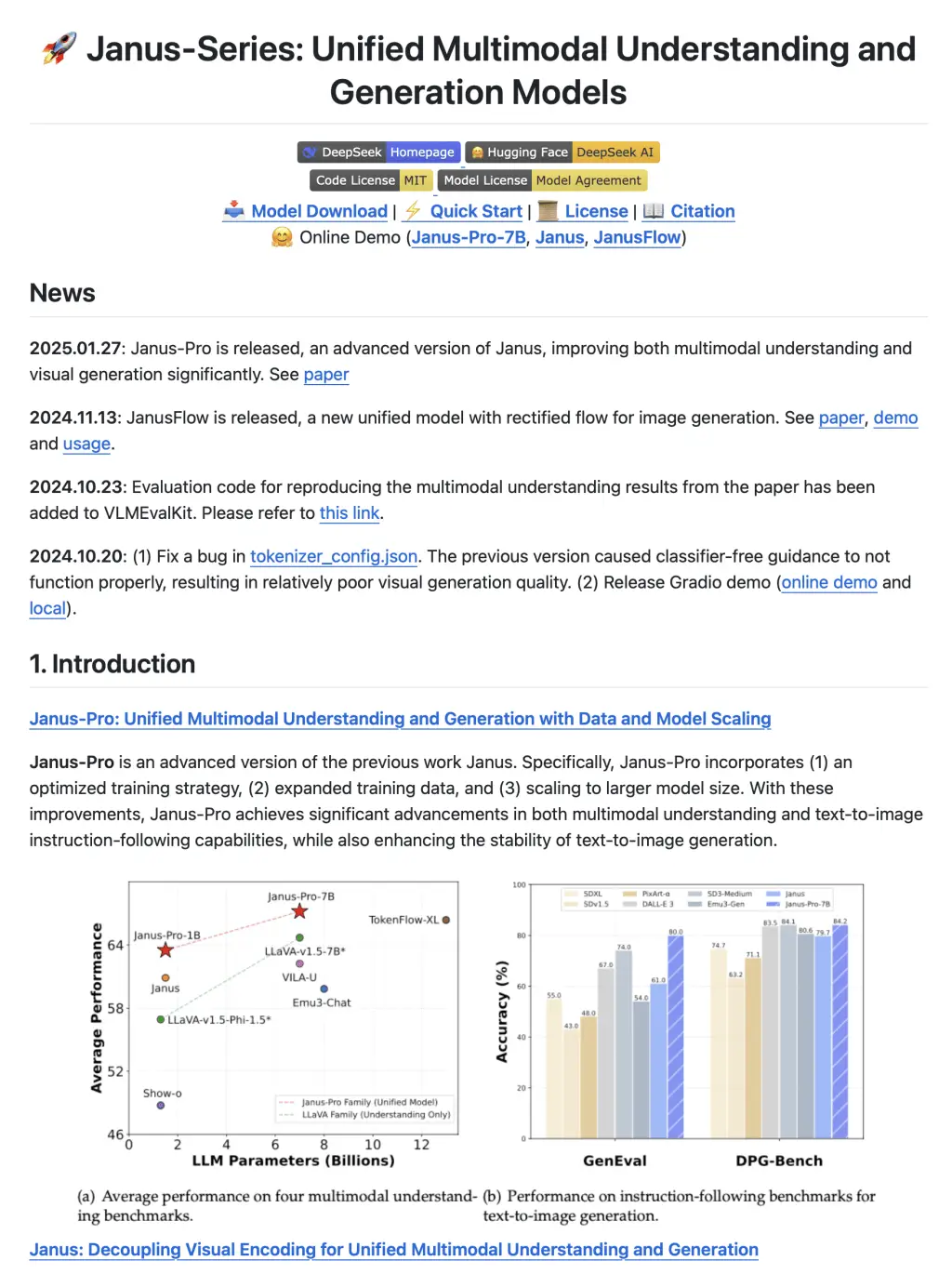
深度求索的研究成果显示,DeepSeek - V3在处理知识类任务上,包括MMLU、MMLU - Pro、GPQA、SimpleQA等,相较于前代DeepSeek - V2.5有了显著进步。其表现已与Anthropic公司于10月推出的Claude - 3.5 - Sonnet - 1022相当。在数学竞赛领域,无论是AIME 2024、MATH还是CNMO 2024,DeepSeek - V3均显著优于其他开源或闭源模型。这一成就凸显了其在学术和知识掌握方面的卓越能力。同时,这也反映了深度求索在人工智能模型研究上的显著进展,令人期待其未来能达到何种高度。
DeepSeek - V3在性能对比中展现出显著优势,这得益于深度求索在研发上所投入的大量资源。这一成就表明,其在模型研发领域的选择是精准且有效的。这一经验对于行业内其他模型研发工作具有一定的参考价值。
生成速度的显著提升
DeepSeek - V3在生成速度上实现了显著进步。其生成速度从原先的20TPS大幅提升至60TPS,相较于V2.5版本,速度提升了三倍。如此之快的生成速度,为用户提供了极为流畅的使用感受。在众多用户眼中,快速生成是一个极为重要的考量因素。

在具体应用中,面对大量文本的处理,DeepSeek - V3能够显著提升生成速度,从而大幅增强工作效率。这一特点体现了其在市场上的竞争优势。企业对软件速度的优化投入显著,这一点对业界同行具有借鉴意义。
元AI科学家的赞赏
田渊栋,Meta AI的研究科学家,对DeepSeek - V3在各方面的进步给予了高度评价,称之为“一项卓越成就”。业内一位知名科学家的肯定,凸显了DeepSeek - V3在专业领域的独特性。这种认可反映了同行的尊敬,同时也说明了DeepSeek - V3达到了专业领域的高质量标准。
田渊栋的认可可能引发更多人士对DeepSeek - V3的关注。此举无疑提升了深度求索公司的声誉。同时,这也激发了公司加大研发力度,以提升产品性能。
较低的训练成本
官方技术论文显示,DeepSeek - V3模型的训练费用达到557.6万美元,相比之下,GPT - 4o等模型的训练费用高达约1亿美元。DeepSeek - V3模型在训练成本上表现优异,成本控制方面表现突出。这一优势为其在市场竞争中赢得价格上的优势提供了坚实基础。
这种成本上的优势可能促使众多企业重新评估,是否采纳深度学习的创新成果。此举亦引发了人工智能领域对如何在减少成本的同时提升模型性能的深入思考。
深度求索公司基本情况
2023年7月17日,深度求索正式成立,其创立者为幻方量化。幻方量化创始人梁文峰在量化投资及高性能计算领域拥有丰富的经验和深厚的背景。在短短半年内,公司便推出了第一代大模型DeepSeek Coder。2024年5月,DeepSeek - V2模型发布,该模型在中文综合能力评测中表现出色,且推理成本极低,因此受到行业关注,被誉为“AI界的拼多多”。
观察可见,该领域的发展势头强劲,持续在技术层面进行革新与拓展。每一次的进步都标志着其在人工智能界稳步提升,逐步确立自身地位的过程。
模型API服务价格情况
DeepSeek V3模型API服务的收费标准为每百万输入tokens0.5元(缓存命中)或2元(缓存未命中),而每百万输出tokens的收费为8元。同时,用户在享受45天的优惠价格体验期。这一价格策略颇具吸引力,有助于在优惠期内吸引更多企业或用户试用,进而增加用户规模和市场占有率。
合理的定价对产品推广至关重要。深度求索公司在定价策略上考虑得相当全面。他们如何平衡成本、利润和市场拓展的关系?我们期待读者在评论区发表见解。同时,欢迎点赞及转发本文,让更多人了解这一科技成果。